{kind=link}
In this blog post, we will explore how to host your very own ChatGPT using the powerful combination of Ollama and OpenWebUI, all powered by VMware Cloud Foundation. By leveraging these cutting-edge technologies, you’ll be able to create a seamless and interactive chatbot experience that will impress your users. Get ready to dive into the world of AI and virtualization as we walk you through the steps to set up your own ChatGPT. Exciting times are ahead, so let’s get started on this journey together!
This walkthrough will only guide you through how to setup Ollama and Open WebUI – you will need to provide your own Linux VM, for my deployment I used Ubuntu 22.04.
Next blog post we will go into customizing and adding onto Ollama and OpenWebUI with for example Automatic1111 and Diffusion and Image Generation LLMs.
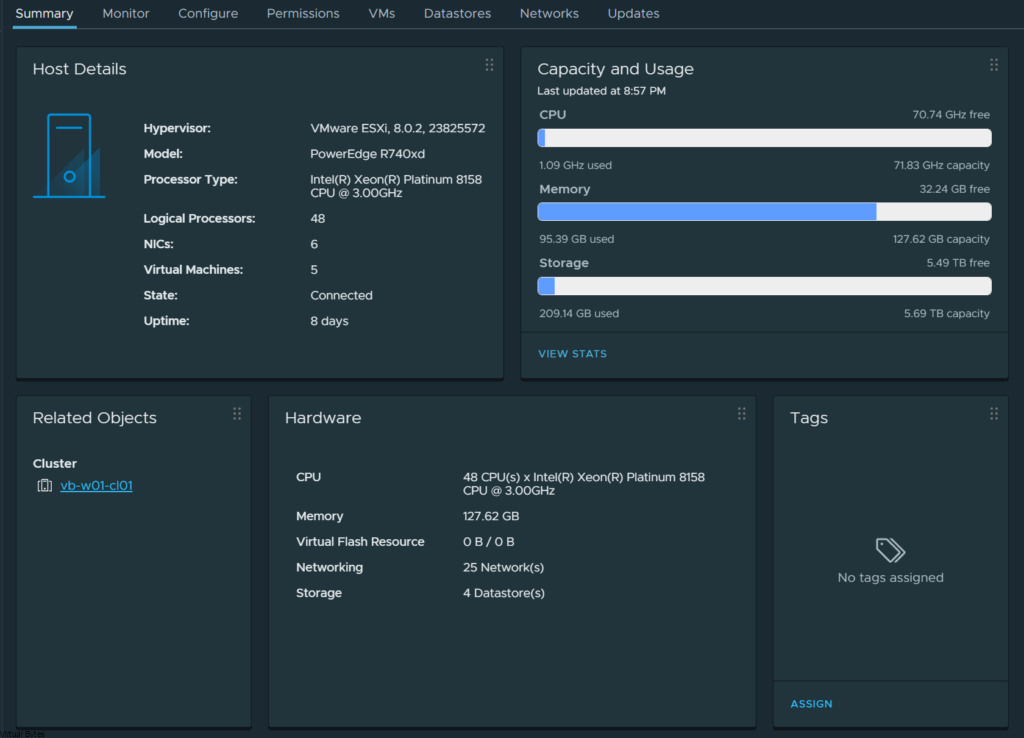
The Hardware:
- 2 x Intel Platinum 8158 3.0GHz 12 Cores
- 1 x Nvidia Tesla P40 24GB DDR5
- 1 x Dell PERC H740P RAID Card
- 4 x 32GB Samsung DDR4 2666MHz (128GB)
- 2 x 50Gb/s Mellanox Connectx-4 Data Traffic
- 4 x 10Gb/s X710 NDC for NSX Overlay
- 1 x Boss S1 w/ M.2 SSD for ESXi Boot
- 2 x 2000 watt PSUs
- 8 x 800GB SAS SSD – Capacity Storage
- 2 x 280GB Intel Optane Storage – Fast Storage



The Virtual Machine:
- Deploy a Ubuntu or any choice of Debian distro if you want to utilize the commands I have apart of this walkthrough.
- Enabling Hardware Device Passthrough for the GPU also apart of your VMX add the following in:
| pciPassthru.use64bitMMIO=”TRUE” pciPassthru.64bitMMIOSizeGB=”128″ |
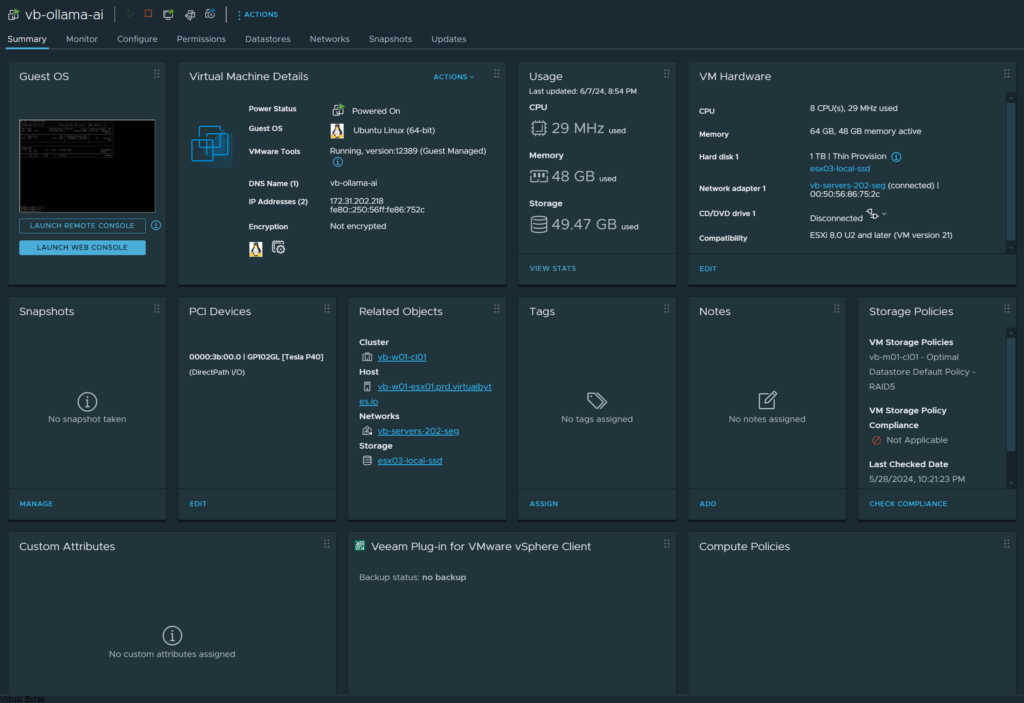
Once the Virtual Machine is deployed, you will want to ensure that your Server or Desktop Hardware is prepared to have a GPU, in my Dell PowerEdge R740XD I have a NVIDIA Tesla P40.
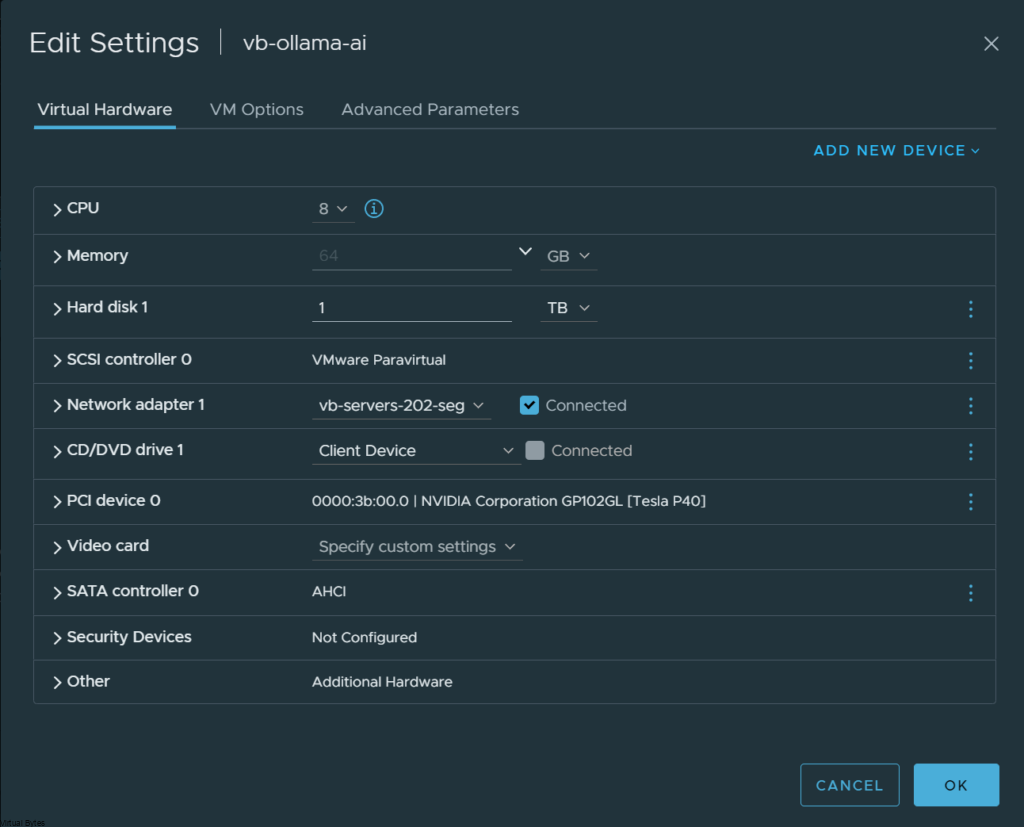
The Specifications:
This will vary, for my initial deployment I setup 8 vCPUs with the Automatic CPU Topology enabled, but this will all depend on your use case, since I have powerful CPUs and lots of memory I can increase the resource allocation later on.
The Software:
Download & Install Ollama:
curl -fsSL https://ollama.com/install.sh | sh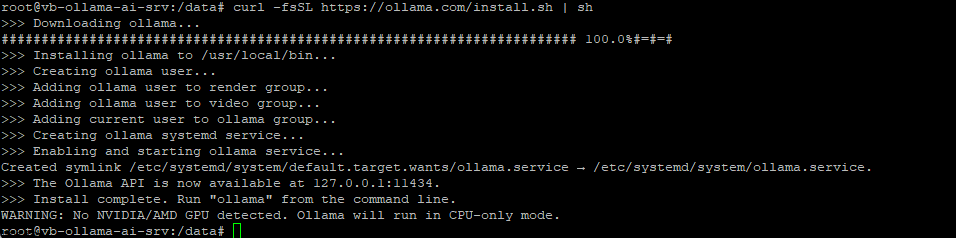
Time to Shutdown The Virtual Machine and Pass Through the NVIDIA Tesla P40
- With the above requirements satisfied, two entries must be added to the VM’s VMX file, either by modifying the file directly or by using the vSphere client to add these capabilities. The first entry is:
| pciPassthru.use64bitMMIO=”TRUE” |
- Specifying the second entry requires a simple calculation. Sum the GPU memory sizes of all GPU devices(*) you intend to pass into the VM and then round up to the next power of two. For example, to use passthrough with 4 16 GB A2 devices, the value would be: 32 + 32 = 64, rounded up to the next power of two to yield 128. Use this value in the second entry:
| pciPassthru.64bitMMIOSizeGB=”128″ |

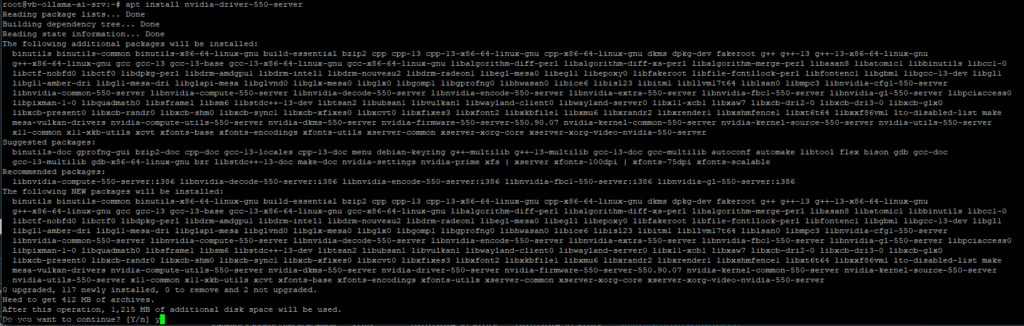
Add Docker’s official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.ascAdd the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get updateNext, we will install docker and all its dependencies:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-pluginNow we will setup the docker container for Open WebUI to run, on port 11434 – Yeah the port number looks like (LLAMA haha)
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainAfter you run the command above, then your webserver should start running – Open up your browser and login! You will be directed to setup a username / email. Once that is done, have fun and enjoy your own private AI!
Now, you will be presented the dashboard for your very own ChatGPT Privately Hosted!

Enjoy! 🙂
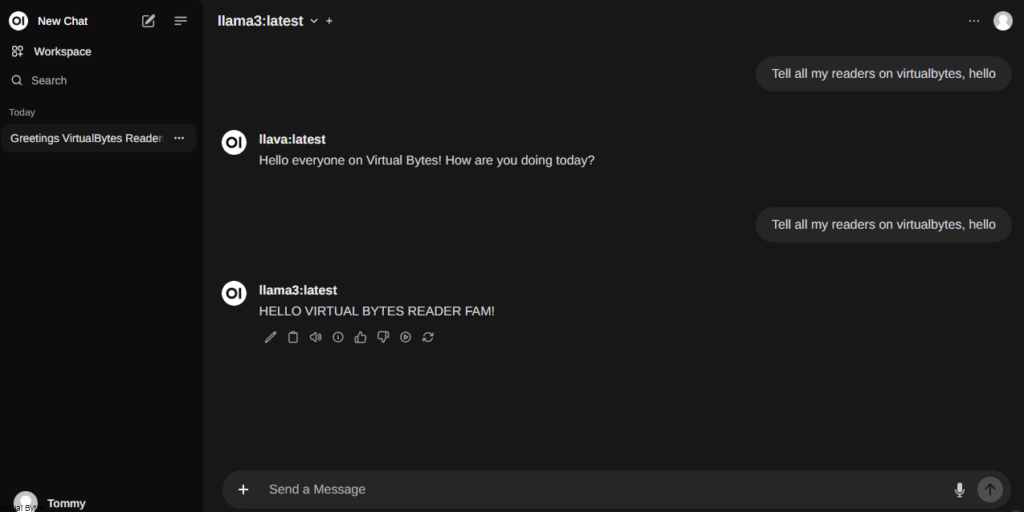
Depending on what LLMs you want to pull here is a example of how to do it via CLI
ollama pull aya

There we pulled aya LLM!